In the previous post, we covered the basics of scheduling model in LLVM. Specifically, per-operand tokens that connect an instruction with models that spell out processor-specific scheduling properties like instruction latency, and the concept of processor resources with different sizes of buffer.
While I was planning to write how scheduling models are used in this post – namely, covering things like instruction scheduler and MCA – the draft was overwhelmed by the sheer amount of content needed to cover just the substrate. In addition, I found that I missed some more advanced yet commonly used constructions in the previous post. So if you’ll excuse me, I’d like to procrastinate writing about MachineScheduler and MCA, leaving it for future Min to worry, and dive into three important scheduling model constructions in this post: number of ProcResource units, ProcResGroup, and super resource.
These three horsemen together enable scheduling models to express hierarchy structure – a concept that we have only scratched the surface previously. Modern microarchitectures often employ complicated processor resource distributions and groupings, like having multiple execution pipes with asymmetric capabilities. It is of paramount importance to express those structures with the things we’re about to cover.
Without further ado, let’s start with the number of ProcResource units!
Number of units in a ProcResource
So far we’ve mentioned things like ProcResource<1> or ProcResource<2> several times without explaining the numbers in the template argument list. That specific argument stands for the number of units in a processor resource.
This property is directly related to the throughput of this resource, namely, how many uops it can process in a given time. To give you a more concrete example, let’s see how LLVM’s scheduling model calculates the reciprocal throughput – a synonym of inverse throughput – of an instruction.
1std::optional<double> Throughput;
2const MCSchedModel &SM = STI.getSchedModel();
3const MCWriteProcResEntry *I = STI.getWriteProcResBegin(&SCDesc);
4const MCWriteProcResEntry *E = STI.getWriteProcResEnd(&SCDesc);
5for (; I != E; ++I) {
6 if (!I->ReleaseAtCycle)
7 continue;
8 unsigned NumUnits = SM.getProcResource(I->ProcResourceIdx)->NumUnits;
9 double Temp = NumUnits * 1.0 / I->ReleaseAtCycle;
10 Throughput = Throughput ? std::min(*Throughput, Temp) : Temp;
11}
12if (Throughput)
13 return 1.0 / *Throughput;The code above is excerpted from MCSchedModel::getReciprocalThroughput: it scans through every write resources in this instruction (represented by its scheduling class, SCDesc) via each resource’s index ProcResourceIdx.
The throughput contributed by each resource used by this instruction is calculated by dividing the number of units (NumUnits) by ReleaseAtCycle, which is the number of cycles reserved on this resource. We eventually take the largest inverse throughput (i.e. smallest throughput) among all the resources as the overall throughput of this instruction.
A single ProcResource with number of unit larger than one is equivalent to multiple identical ProcResource instances. For example, let’s say we have the following scheduling model:
1def IEX : ProcResource<3>;
2
3def : WriteRes<WriteIMul, [IEX]>;In this model, we assign IEX (integer execution pipes) to WriteIMul – a SchedWrite token that represents integer multiplication instructions. This is equivalent to having three individual integer pipes – IEX0, IEX1, and IEX2, where any of them can do multiplications:
1def IEX0 : ProcResource<1>;
2def IEX1 : ProcResource<1>;
3def IEX2 : ProcResource<1>;Having (effectively) three available pipes also means that we can dispatch three multiplications in parallel! Take the following RISC-V assembly snippet as an example, assuming we’re dispatching them into this model with an issue width of 6. Since there is no Read-After-Write (RAW) dependencies among the instructions, we can dispatch them in parallel.
mul a1, a1, a2
mul t4, t4, t5
mul t0, t0, t1What we’re interested in here, is how each of them consumes processor resources. We can visualize this process with the following resource consumption table:
| instruction | IEX0 | IEX1 | IEX2 |
|---|---|---|---|
| mul a1, a1, a2 | Consumed | Available | Available |
| mul t4, t4, t5 | Consumed | Available | Consumed |
| mul t0, t0, t1 | Consumed | Consumed | Consumed |
The instructions are dispatched from top to bottom. For each of the instruction, we randomly1 look for an empty pipe to dispatch it into.
Alternatively, we can rewrite this table into a more compact format:
| instruction | Consumed IEX units |
|---|---|
| mul a1, a1, a2 | 1 / 3 |
| mul t4, t4, t5 | 2 / 3 |
| mul t0, t0, t1 | 3 / 3 |
In this table, we focus on the number of consumed units in def IEX : ProcResource<3>, where 2 / 3 means “two out of three total units are consumed”. This table will come into handy later when we’re discussing more advanced scheduling model concepts.
But for now, let’s step back for a second: if dispatching to ProcResource<3> is equivalent to doing the same thing against three individual ProcResource<1> where we can dispatch an instruction to any of them…
Haven’t we seen something similar in the previous post already?
That’s right! It’s ProcResGroup. This is what we have after rewriting the same model with ProcResGroup:
1def IEX0 : ProcResource<1>;
2def IEX1 : ProcResource<1>;
3def IEX2 : ProcResource<1>;
4
5def IEX : ProcResGroup<[IEX0, IEX1, IEX2]>;
6
7def : WriteRes<WriteIMul, [IEX]>;Both models express the fact that multiplication instructions can run on any of the three integer pipes.
But then it prompts a question: if they’re so similar, why do we have two different syntax in the first place?
The key, as it turns out, is the fact that we were dealing with three identical pipes in the previous example. In reality, we might not always have execution units with the same capabilities. For example, here is a more realistic design:

In this design, only two out of three pipes are capable of doing multiplications; divisions and cryptographies, on the other hand, can only run on one of the pipes.
The rationale behind this design is that complex operations like division or cryptography usually take up a larger chip area and draw more power, while being less commonly used. So it’s pretty common to have a heterogeneous layout where certain operations are only available in a subset of execution units.
With only a single def IEX : ProcResource<3>, it’ll be more difficult to express the resources used by each kind of instructions because currently there is no way to say something like “WriteIDiv uses the second unit of IEX”:
1def IEX : ProcResource<3>
2
3// Simple arithmetics, like ADD
4def : WriteRes<WriteIALU, [IEX]>;
5// Multiplication
6def : WriteRes<WriteIMul, [/*IEX[0] and IEX[2]??*/]>;
7// Division
8def : WriteRes<WriteIDiv, [/*IEX[1]??*/]>;
9// Cryptography
10def : WriteRes<WriteCrypto, [/*IEX[2]??*/]>;On the contrary, it’s much more straight forward to express it with the ProcResGroup we had introduced in the previous post:
1def IEX0 : ProcResource<1>;
2def IEX1 : ProcResource<1>;
3def IEX2 : ProcResource<1>;
4
5def IntegerArith : ProcResGroup<[IEX0, IEX1, IEX2]>;
6def IntegerMul : ProcResGroup<[IEX0, IEX2]>;
7
8// Simple arithmetics, like ADD
9def : WriteRes<WriteIALU, [IntegerArith]>;
10// Multiplication
11def : WriteRes<WriteIMul, [IntegerMul]>;
12// Division
13def : WriteRes<WriteIDiv, [IEX1]>;
14// Cryptography
15def : WriteRes<WriteCrypto, [IEX2]>;As a quick recap: by consuming ProcResGroup<[IEX0, IEX2]>, a multiplication instruction might run on either IEX0 or IEX2 during runtime.
It is worth pointing out that with this model, we have to deal with resource consumptions that go across different ProcResource and ProcResGroup. For instance, when we dispatch a cryptography instruction, the instruction not only consumes IEX2 but also effectively decreases the number of available units in IntegerArith and IntegerMul – which is what multiplication consumes – because IEX2 presents in both ProcResGroup.
In order to account for overlapping ProcResource and ProcResGroup, for each ProcResource or ProcResGroup used by an instruction, LLVM actually inserts an implicit processor resource usage for every ProcResGroup it overlaps. Using the snippet above as an example, this is what it looks like after such “expansion”:
1// Simple arithmetics, like ADD
2def : WriteRes<WriteIALU, [IntegerArith]>;
3// Multiplication
4def : WriteRes<WriteIMul, [IntegerMul, IntegerArith]>;
5// Division
6def : WriteRes<WriteIDiv, [IEX1, IntegerArith]>;
7// Cryptography
8def : WriteRes<WriteCrypto, [IEX2, IntegerArith, IntegerMul]>;A cryptography now consumes not only IEX2, but also one IntegerArith unit and one IntegerMul unit upon dispatch. So if we dispatch the following RISC-V instruction sequence2:
mul s0, s0, a2
sha256sum0 a0, a1
mul a3, a3, t0Here is what happens at cycle 0:
| instruction | IntegerArith | IntegerMul | IEX2 |
|---|---|---|---|
| mul s0, s0, a2 | 1 / 3 | 1 / 2 | 0 / 1 |
| sha256sum0 a0, a1 | 2 / 3 | 2 / 2 | 1 / 1 |
| mul a3, a3, t0 | 3 / 3 | FAIL TO CONSUME | 1 / 1 |
The first multiplication instruction consumes both IntegerArith and IntegerMul. Because IntegerArith has overlapping resources with IntegerMul – IEX0 and IEX2, to be precise.
Similarly, when it comes to the sha256sum0 instruction, it increases the number of consumed resources on not just IEX2 but IntegerArith and IntegerMul as well. Lastly, for the last multiplication instruction, its attempt to acquire IntegerMul will fail because we no longer have spare capacity in that resource, which causes the instruction to stall during the dispatch stage, namely, a dispatch hazard.
ProcResGroup gives you the ability to reference a subset of execution units, which is suitable for modeling units with heterogeneous capabilities. And as it turns out, there is actually a second way to reference subsets of execution units – super resource.
Super resource
Super resource allows us to construct a hierarchy between two ProcResource instances (NOT ProcResGroup). In this relationship, the child ProcResource represents a subset of units from the parent ProcResource.
To give you a better idea, let’s see a real-world example from the Load / Store Unit (LSU) in AMD Zen3.
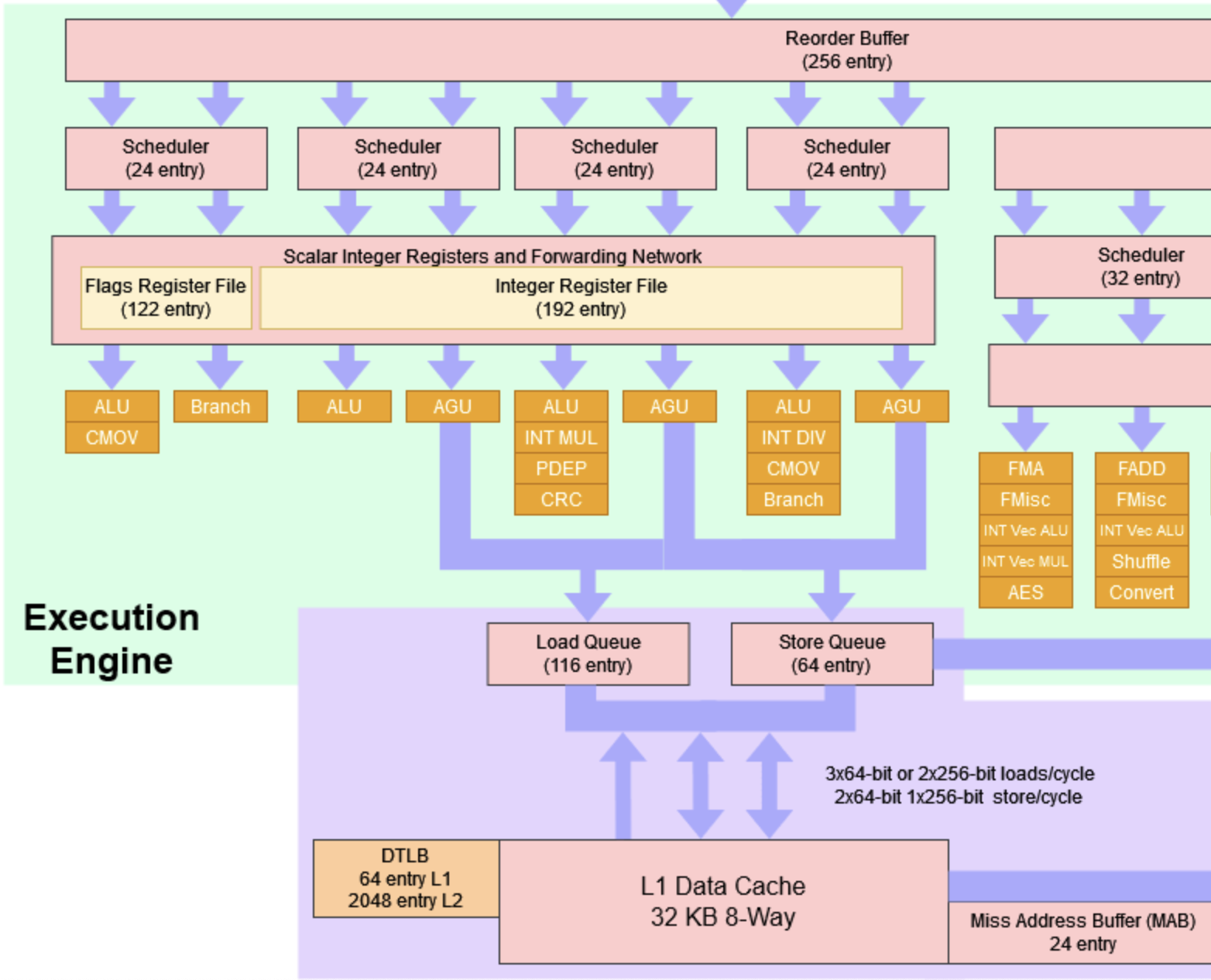
The diagram above shows the LSU part of Zen3’s microarchitecture. There are three arrows between load & store queues and L1 Data Cache, along with an equal number of AGUs (Address Generation Unit) positioned above the queues.
You might notice that among all three arrows, which are load and store pipes, between the queues and L1 Data Cache, only two of them goes down (indicating stores) while there are three going up (indicating loads). This reveals that all three available pipes are capable of loading data, while only two of them (don’t care which two of them though) can store data. Importantly, each pipe can either load or store data at any given time, but not both simultaneously.
This structure is described by the following code in Zen3’s scheduling model:
1def Zn3LSU : ProcResource<3>;
2
3let Super = Zn3LSU in
4def Zn3Load : ProcResource<3> {
5 ...
6}
7
8let Super = Zn3LSU in
9def Zn3Store : ProcResource<2> {
10 ...
11}Zn3Load and Zn3Store are processor resources representing the load and store pipes, respectively. Both of them designate Zn3LSU – which represents the entire LSU – as their super resource via the Super field.
By designating Zn3LSU as their super resource, both Zn3Load and Zn3Store are essentially representing a subset of all three pipes from Zn3LSU – 2 pipes for Zn3Store and 3 for Zn3Load, coinciding with what we saw from Zen3’s microarchitecture diagram earlier.
Put it differently, a unit from Zn3LSU can either be allocated as a load or a store pipe, while no more than two store pipes are allowed to exist at any given time.
LLVM implements super resource in a really similar way to how it implements ProcResGroup – by expanding ProcResource that has super resources. Let me explain this using the snippet below which shows some Zn3Load and Zn3Store usages.
1def Zn3LSU : ProcResource<3>;
2
3let Super = Zn3LSU in
4def Zn3Load : ProcResource<3>;
5
6let Super = Zn3LSU in
7def Zn3Store : ProcResource<2>;
8...
9// Loads, stores, and moves, not folded with other operations.
10defm : Zn3WriteResInt<WriteLoad, [Zn3AGU012, Zn3Load], ...>;
11defm : Zn3WriteResInt<WriteStore, [Zn3AGU012, Zn3Store], ...>;In this snippet, WriteLoad – the SchedWrite for some of the X86 load instructions – uses Zn3AGU012 and Zn3Load while WriteStore – the SchedRead for some of the X86 store instructions – has a similar resource usage of Zn3AGU012 and Zn3Store.
LLVM effectively expands the Zn3Load and Zn3Store usages in these two SchedWrite entries into:
1defm : Zn3WriteResInt<WriteLoad, [Zn3AGU012, Zn3Load, Zn3LSU], ...>;
2defm : Zn3WriteResInt<WriteStore, [Zn3AGU012, Zn3Store, Zn3LSU], ...>;That’s right! Similar to how ProcResGroup implicitly inserts resource usages of overlapping ProcResGroup, LLVM also implicitly inserts resource usages of super resource, Zn3LSU, into the list.
With the following sequence of X86 load and store instructions:
movq %r9, (%rbx) # store
movq 4(%r8), %rax # load
movq %r10, (%rcx) # storeThey’ll have the following resource consumptions upon dispatch (Zn3AGU012 is omitted from this table for simplicity):
| instruction | Zn3Load | Zn3Store | Zn3LSU |
|---|---|---|---|
| movq %r9, (%rbx) | 0 / 3 | 1 / 2 | 1 / 3 |
| movq 4(%r8), %rax | 1 / 3 | 1 / 2 | 2 / 3 |
| movq %r10, (%rcx) | 1 / 3 | 2 / 2 | 3 / 3 |
Whenever a store (e.g. movq %r9, (%rbx)) is being dispatched, it increases the counters of both Zn3Store and Zn3LSU. Similarly, a load instruction increases both Zn3Load and Zn3LSU counters.
Let’s use the following consecutive store instructions to show how we throttle the number of store pipes to 2:
movq %r9, (%rbx) # store
movq %rax, (%r8) # store
movq %r10, (%rcx) # storeThis snippet produces the following resource consumption table:
| instruction | Zn3Load | Zn3Store | Zn3LSU |
|---|---|---|---|
| movq %r9, (%rbx) | 0 / 3 | 1 / 2 | 1 / 3 |
| movq %rax, (%r8) | 0 / 3 | 2 / 2 | 2 / 3 |
| movq %r10, (%rcx) | 0 / 3 | FAIL TO CONSUME | 3 / 3 |
The last instruction fails to consume Zn3Store, because it only has a total of 2 units.
In other words, the last instruction in this case is throttled by Zn3Store, despite the fact that there are enough number of LSU pipes.
And that, is how Zen3 uses super resource to set a cap on the number of store pipes in its scheduling model.
ProcResGroup v.s. Super resource
So far, we have learned how to use ProcResGroup and super resource. Naturally we want to ask: what are their actual differences and, more importantly, when should I use them?
Conceptually, both super resource and ProcResGroup provide a way to reference a subset of a larger collection of hardware units. Super resource creates a “slice” of an existing ProcResource; ProcResGroup approaches this from an opposite direction: it combines multiple smaller ProcResource into a larger set, so that we can either reference to the larger set or the original individual resource.
The main difference between them comes up when execution pipes have certain kinds of partially overlapping capabilities, like this:

First, let’s (try to) describe this model with super resource in the following way:
1// Note: this is the WRONG approach
2def IEX : ProcResource<3>;
3
4let Super = IEX in {
5 def IntegerArith : ProcResource<2>;
6 def IntegerMul : ProcResource<2>;
7 def IntegerDiv : ProcResource<1>;
8}
9
10// Simple arithmetics, like ADD
11def : WriteRes<WriteIALU, [IntegerArith]>;
12// Multiplication
13def : WriteRes<WriteIMul, [IntegerMul]>;
14// Division
15def : WriteRes<WriteIDiv, [IntegerDiv]>;In hindsight, this model looks correct: two out of three pipes can be allocated to MUL or ALU, while only a single pipe can be used for divisions. But things start to get off the track when we run the following RISC-V snippet through this model.
mul a1, a1, a2
mul t4, t4, t5
div s0, s0, t0First, let’s expand those WriteRes entries:
1// Simple arithmetics, like ADD
2def : WriteRes<WriteIALU, [IntegerArith, IEX]>;
3// Multiplication
4def : WriteRes<WriteIMul, [IntegerMul, IEX]>;
5// Division
6def : WriteRes<WriteIDiv, [IntegerDiv, IEX]>;IntegerArith, IntegerMul, and IntegerDiv all have IEX as its super resource, which is implicitly inserted into the list of resource usages in all three entries.
With this expansion, we can pan out the (plausibly correct) resource consumption table:
| instruction | IntegerArith | IntegerMul | IntegerDiv | IEX |
|---|---|---|---|---|
| mul a1, a1, a2 | 0 / 2 | 1 / 2 | 0 / 1 | 1 / 3 |
| mul t4, t4, t5 | 0 / 2 | 2 / 2 | 0 / 1 | 2 / 3 |
| div s0, s0, t0 | 0 / 2 | 2 / 2 | 1 / 1 | 3 / 3 |
Again, each instruction gets the resources they demanded and everything looks correct – until you realize that if both IEX1 and IEX2, the multiplication-capable pipes, have already been consumed, how can the last instruction be dispatched to IEX1, the only pipe that is capable of doing division?
Now, you might try to fix this by assigning a different super resource to IntegerDiv, let’s say IntegerMul:
1// ????
2let Super = IntegerMul in
3def IntegerDiv : ProcResource<1>;But then we will run into the same problem if we have the following RISC-V snippet, in which add instructions use IntegerALU:
add a1, a1, a2
add t4, t4, t5
div s0, s0, t0Because the first two add instructions will already consume both IEX0 and IEX1 before division tries to grab IEX1 that is no longer available.
The root cause for the problem we have here is that we cannot declare both IntegerMul and IntegerALU as the super resource of IntegerDiv. Super resource is only effective if you can organize the ProcResource hierarchy into a tree.
Take the processor model we used at the beginning of this post as the example, we can easily organize their processor resources into a tree as shown in the figure below.

On the other hand, the processor model we saw in this section can only be expressed with a DAG:

Of course, we can easily describe this model with DAG structure using ProcResGroup:
1def IEX0 : ProcResource<1>;
2def IEX1 : ProcResource<1>;
3def IEX2 : ProcResource<1>;
4
5def IntegerArith : ProcResGroup<[IEX0, IEX1]>;
6def IntegerMul : ProcResGroup<[IEX1, IEX2]>;
7
8// Simple arithmetics, like ADD
9def : WriteRes<WriteIALU, [IntegerArith]>;
10// Multiplication
11def : WriteRes<WriteIMul, [IntegerMul]>;
12// Division
13def : WriteRes<WriteIDiv, [IEX1]>;After expansion, we effectively have the following WriteRes entries:
1// Simple arithmetics, like ADD
2def : WriteRes<WriteIALU, [IntegerArith]>;
3// Multiplication
4def : WriteRes<WriteIMul, [IntegerMul]>;
5// Division
6def : WriteRes<WriteIDiv, [IEX1, IntegerArith, IntegerMul]>;Now WriteIDiv consumes not just IEX1 but also IntegerArith and IntegerMul – the predecessors of the division resource in the DAG we just saw.
If we run this model over one of the earlier snippets:
| instruction | IntegerArith | IntegerMul | IEX1 |
|---|---|---|---|
| mul a1, a1, a2 | 0 / 2 | 1 / 2 | 0 / 1 |
| mul t4, t4, t5 | 0 / 2 | 2 / 2 | 0 / 1 |
| div s0, s0, t0 | 1 / 2 | FAIL TO CONSUME | 1 / 1 |
The division instruction is unable to be dispatched, because it failed to consume the IntegerMul resource – and this behavior is something we expect.
I hope you’re now convinced that ProcResGroup is more flexible and more generic than super resource, because it can express models with either tree or non-tree structures. This comes unsurprised as ProcResGroup was actually invented later than super resource.
That said, super resource might come handy when we only care about the number of processor units and referencing the exact pipes is less important. For example, in an extreme situation where there are a total of 12 execution pipes in a model, instead of spelling out all processor resources like this3:
1def IEX0 : ProcResource<1>;
2def IEX1 : ProcResource<1>;
3...
4def IEX11 : ProcResource<1>;
5
6// I make up these groupings, the point is that it's
7// quite cumbersome to reference every IEX pipe they use.
8def IntegerArith : ProcResGroup<[IEX0, IEX1, ...]>;
9def IntegerMul : ProcResGroup<[IEX6, IEX8, ...]>;It’s certainly easier and more concise to write:
1def IEX : ProcResource<12>;
2
3let Super = IEX in {
4 def IntegerArith : ProcResource<12>;
5 def IntegerMul : ProcResource<6>;
6}Summary
To conclude, in this post we discussed several options to express processor resources with hierarchy structures. Notably, ProcResGroup and super resource. The takeaway is that ProcResGroup is generally more flexible and versitile than the other options, but can be quite verbose in some cases, in which super resource or even just plain ProcResource with multiple units is more desirable.
The actual dispatching algorithm in real processors is much more complicated, but let’s just assume it looks for available pipes without any specific order. ↩︎
Again, using a processor with issue width of 6 ↩︎
Even we can simplify it with
foreachand some other TableGen magic, I’m sure it’s still more verbose than using super resource. ↩︎